Statistical approach to a 2 by 2 crossover design
Question
This blog post is taken from a question I answered on cross validated during the week-end. I have had this blog on the backburner for a while, and that is as good of an opportunity to properly start it as I will get. You can find the q & a thread here: cross-validated. The original question from user AB108 is:
I’m conducting a randomized crossover trial with 16 participants, where each
subject receives two interventions (sub-occipital muscle inhibition and deep
breathing). For each intervention, heart rate variability (HRV) metrics (e.g.,
RMSSD and HF) are recorded before and after the intervention.
I’m aiming to determine whether one intervention leads to greater
parasympathetic activation than the other, based on these HRV measures.
The design involves: Repeated measures (pre and post) Two conditions per
participant A small sample size (n = 17) A few potential covariates (e.g.,
stress level, respiratory rate)
What statistical approach would you recommend for analyzing this kind of data?
Would you use a method that compares pre/post differences (deltas), or would
you suggest a model that incorporates all measurements directly? I'm
particularly interested in approaches that account for within-subject
variability and repeated measures.
Here are initial thoughts about the question:
- It is actually two questions in one
- I have not heard of crossover design before
- There are multiple outcomes of interest and it is not clear how the inquirer plans to combine or include them in his analysis.
- AB108 (the inquirer) is interested about including covariates in the analysis.
Two questions in one
The first question is about the desirability of analysing the pre-post difference in outcomes. For example, this could be taking the difference in RMSSD. Typically, a pre-post analysis would denote taking the difference of the outcome after versus the outcome before receiving a treatment, but here we are comparing two treatments: sub-occipital muscle inhibition and deep breathing. So we just take the difference in outcome between two treatments, and forget about the baseline (i.e. not treatment).
In general, a pre-post analysis is a waste of time. You can often argue that something unrelated to the difference of interest happens between the two interventions given to a subject. That makes it difficult to defend a causal statement.
Nevertheless, taking a pre-post difference does control for what is known as time-invariant subject characteristics. Those are things like your natural hair color or your neuroticism. To be a bit more precise, a time-invariant characteristic is something that stays constant during the period of the experiment. That makes taking the pre-post difference a good tactic to reduce the variation of the outcome of interest (for ex. the RMSSD here). At equal sample size, this increases the power of a statistical test on that difference.
The second question: would you suggest a model that incorporates all measurements directly? is unclear. Namely if it is suggested to include all measurements in a model. Assuming they are valid, I would not exclude measurements from an analysis, regardless of whether I am specifying a statistical model or not.
I chose to interpret it as whether it is worth it to specify a model. A model lets us control for additional measured covariates such as stress level, so it can be advantageous. However, including additional covariates is touchy, especially with a small sample size. The covariates have to be strongly correlated with the outcomes and at most weakly correlated with the treatment or they could induce bias and/or variation in the difference estimate between sub-occipital muscle inhibitiion and deep breathing. That’s a judgment call that I leave to the subject-matter expert.
What’s a crossover design?
The crossover design is a clever way to control for the time-invariant characteristics of subjects while removing eventual bias from the time spent in observation. For example, you can imagine that bias appearing with subjects getting more comfortable with the experimental setting between the initial and the post-treatment outcome measurements.
To control for bias due to such uncontrolled time-dependent effects, a crossover design split the subjects into treatment branches. Each branch receives the treatments or lack thereof (for ex. placebo), in a different sequence. In the question, the inquirer is tackling a case with two observations, pre and post, and two treatment, sub-occipital muscle inhibition and deep breathing. Subjects in the first branch then get one treatment, say muscle inhibition, at the pre observation period, while subjects in the second treatment branch receive deep breathing in the pre period. In the second period of observation, post, each branch gets the alternative treatment.
This split into sequences or branches of treatment sounds like a lot of trouble, but it allows control for time-dependent effects across subjects in the analysis. Concretely, this can be done with a statistical model or by simply taking the difference of the treatment differences between the treatment branches. Shared time-dependent effects between treatment branches are removed by taking this difference.
In theory, a crossover design is great because it isolates the difference in treatment effects from spurious time-related things better while keeping statistical power relatively high with its measurement of within-subject outcomes. I recommend looking at this clear review paper for a better intuition of the experimental design: On the proper use of the crossover design in clinical trials
In practice, you have to account with a so-called wash-out effect. That is the effect of one treatment having an effect on the next one given to a subject.
Multiple outcomes of interest
There are multiple outcomes of interest: RMSSD, HF and fellow user jginestet points to a paper (An overview of heart rate variability metrics) listing 26 measures relevant to the analysis of heart rate variability (HRV).
Multiple outcomes is a hornet nest for analysts. Outcomes can be combined in all sorts of way during an analysis with more or less unsavory results. I chose to ignore this problem and focus on the analysis of a single outcome. User jginestet tackles this issue directly and gives relevant recommendations with regard to the multiple comparison problems, multivariate statistical modeling and small sample analysis.
Tackling the first question
Whether to use a method that compares pre/post differences?
The classical two-step approach to crossover design analysis with 2 repeated measures per participant suggests comparing the pre-post differences first. This gives a within-subject effect estimate but doesn’t control for period effects (e.g., getting used to the experiment). That’s where the second step of the approach comes in.
After the first step, take the means of these differences per treatment branch (two branches in this design). In the second step, compute the difference between these two means (e.g., muscle inhibition → deep breathing average minus deep breathing → muscle inhibition average). This removes any additive period effect.
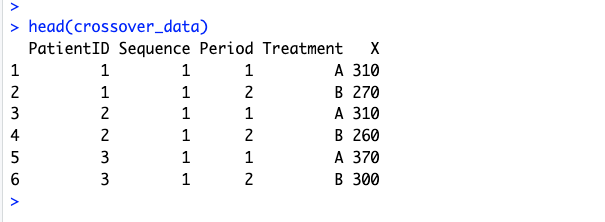
In practice, I’d handle the first step manually and use software to do an independent samples t-test at the second step. Here’s an example in R:
# First step: difference within subjects
crossover_patient_split <- split(crossover_data, crossover_data$PatientID)
patient_diff_df <- do.call("rbind",
lapply(crossover_patient_split, FUN=function(x) {
data.frame(
period_diff=(x$X[x$Period == 1] - x$X[x$Period == 2]), # Corrected syntax
PatientID=x$PatientID[1],
Sequence=x$Sequence[1] # Seq. 1: A→B, Seq. 2: B→A
)
})
)
# Second step: t-test on the difference between sequences
t.test(
period_diff ~ Sequence,
data=patient_diff_df,
var.equal=TRUE
)
In On the proper use of the crossover design in clinical trials, they recommend a Wilcoxon rank-sum test instead of a t-test if non-normality is suspected in the within-subject differences. With small samples and continuous outcomes, non-normality often arises due to outliers.
Tackling the second question
Would you suggest a model that incorporates all measurements directly?
In the $2 \times 2$ crossover design, the main advantage of a model is its ability to include time-varying covariates like respiratory rate. I also find this approach more straightforward: you directly control for subject and period effects while directly estimating the treatment difference.
Here’s a R linear regression example producing the same t-statistic as the two-step approach:
fit1 <- lm(X ~ Treatment + factor(PatientID) + Period, data=crossover_data)
summary(fit1)
The Treatment variable could represent muscle inhibition or deep breathing
depending on the prefered interpretation. The model explicitely controls for
subject and period effects. The treatment branch mentioned above isn’t
explicitly included but allows the identification of the period effect.
A peek at the data structure: